大模型学习全攻略 从零基础到AI专家的系统性路线图
随着ChatGPT、GPT-4等大型语言模型的崛起,人工智能进入了一个全新的时代。无论你是对AI充满好奇的零基础新手,还是希望深入技术开发的大学生,掌握大模型相关知识已成为未来竞争力的关键。本文为你梳理一条清晰、系统、可执行的学习路线,助你从入门到精通。
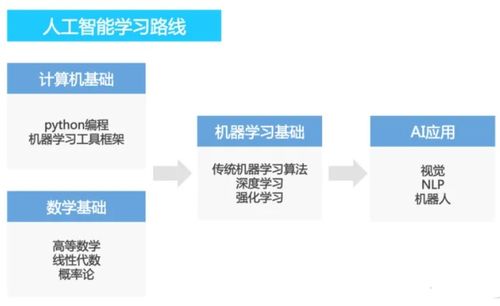
一、 基础筑基阶段(1-3个月)
目标:建立对人工智能和机器学习的基本认知,为理解大模型打下坚实基础。
- 数学基础:重点复习线性代数(向量、矩阵)、概率论与数理统计(贝叶斯、分布)、微积分(梯度、导数)。不必追求高深,理解核心概念即可。
- 编程基础:Python是AI领域的绝对主流。需熟练掌握其基本语法、数据结构、常用库(如NumPy, Pandas),并了解面向对象编程。
- 机器学习入门:学习经典机器学习算法(如线性回归、逻辑回归、决策树、SVM、聚类)的基本原理与应用。推荐吴恩达的《机器学习》课程或李航的《统计学习方法》。
- 深度学习初步:理解神经网络的基本构成(神经元、层、激活函数)、训练过程(前向传播、反向传播、梯度下降)及框架使用(如PyTorch或TensorFlow,建议首选PyTorch)。
二、 核心深入阶段(3-6个月)
目标:深入理解自然语言处理(NLP)和现代大模型的核心架构与技术。
- 自然语言处理基础:学习词袋模型、Word2Vec、ELMo等词向量表示方法,掌握RNN、LSTM、GRU等序列模型。
- Transformer架构精讲:这是大模型的基石。必须透彻理解其核心组件:自注意力机制(Self-Attention)、位置编码、编码器-解码器结构。建议精读原始论文《Attention Is All You Need》并动手实现一个简易版。
- 预训练语言模型:系统学习BERT(双向编码器代表)、GPT系列(自回归生成模型代表)等里程碑模型的原理、预训练任务(如MLM, NSP)和微调方法。
- 大模型关键技术:深入理解提示工程、指令微调、思维链、人类反馈强化学习等让大模型“智能涌现”的关键技术。
三、 实践与应用阶段(持续进行)
目标:通过项目实践,掌握大模型的调用、微调、部署及应用开发能力。
- API调用与提示工程:熟练使用OpenAI、文心一言、通义千问等主流大模型的API。精通提示词撰写技巧,学会零样本、少样本、思维链等高级提示方法。
- 模型微调实战:学习使用LoRA、QLoRA等高效微调技术,在特定领域数据上微调开源大模型(如Llama、ChatGLM、Qwen),使其适应专业任务。
- 应用开发项目:结合LangChain、LlamaIndex等框架,开发基于大模型的智能应用,如知识库问答、AI助手、内容生成工具等。这是将技术转化为价值的关键一步。
- 参与开源与社区:在GitHub上阅读和复现优秀项目,在Hugging Face上体验和下载模型,在知乎、Reddit等社区交流讨论,保持与前沿同步。
四、 进阶与前沿阶段(长期探索)
目标:跟踪前沿,并向AI专家或研究者方向发展。
- 模型架构与优化:研究MoE、混合专家模型、更高效的自注意力变体等前沿架构,了解模型压缩、量化、蒸馏等优化技术。
- 多模态大模型:探索CLIP、DALL-E、Sora等多模态模型的原理,理解视觉、语言、音频的融合与生成。
- AI系统与部署:学习大规模分布式训练、模型服务化、性能优化等工程化知识,了解如何将大模型产品化。
- 研究方向:关注Agent(智能体)、强化学习与大模型结合、具身智能、可信AI(安全性、可解释性、公平性)等顶级研究课题。
给新手和大学生的建议:
保持耐心:AI知识体系庞大,切勿急于求成。打好基础远比追逐热点重要。
动手优先:理论学习后,立即通过代码和项目实践巩固。从“跑通第一个例子”开始。
善用资源:充分利用国内外优质课程(Coursera, 斯坦福CS224n)、开源代码、技术博客和论文。
构建作品集:将你的学习项目、实验、笔记整理成GitHub仓库或技术博客,这是你能力的最好证明。
这条路线图并非一成不变的铁轨,而是一份导航图。你可以根据自身兴趣(如更偏重应用开发还是理论研究)调整侧重点。最重要的是开始行动,并持续学习。在这个AI快速演进的时代,保持好奇心和强大的学习能力,你将一步步从AI新人成长为驾驭大模型的专家。
如若转载,请注明出处:http://www.yicesuan168.com/product/53.html
更新时间:2026-02-28 15:24:57